Technical information about the GVC Emotion Recognition
GVC Neuro - Emo Analysis
Introduction
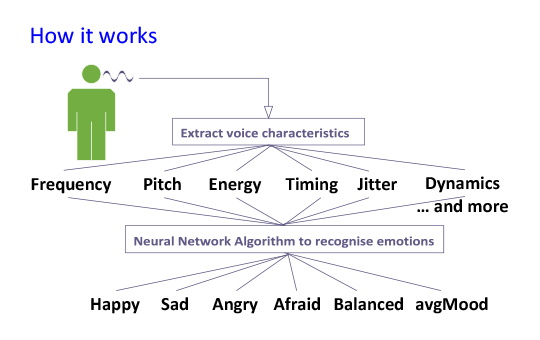
The GVC - Neuro & Emo Analysis Service detects emotions directly from the voice and from speech samples.
The Emotion Recognition software of Good Vibrations Company is web based. This enables a straightforward implementation in your own software. We use standard protocols like WS, WSS and JSON.
License
GVC provides its' software on the basis of license agreements. After the license agreement has been concluded, you receive a Token that authorizes you to use the web service until the agreed expiration date.
Delivery of speech data
Speech samples must be delivered using the WS or WSS protocol. We currently support primarily PCM. Other audio formats, like WAV and MP3, are foreseen to be supported in the near future. A server connection is for a mono channel. If you want to handle a stereo channel you could combine the stereo channels to a mono channel or use two separate connections.
Emotion probability responses
The analysis of the speech results in an assessment of the probability of specific emotions in the individuals’ voice. The emotion probabilities of the signal processed via the voice channel will be reported in a fixed interval. The length of the interval in seconds can be configured with the URL key "ResponseTime". The server will then send a response in JSON format.
Processing of the speech sample
The speech sample is processed in 2 phases. In the first phase we calculate some essential indicators that characterise the voice. These indicators are for example pitch, intensity, spectral slope, dynamics and jitter.
Neural Network
In the second phase we predict the emotions from the indicators using a neural network. The neural network is trained, among others, with the scientifically annotated speech emotion databases of several leading universities.
Connection Setup
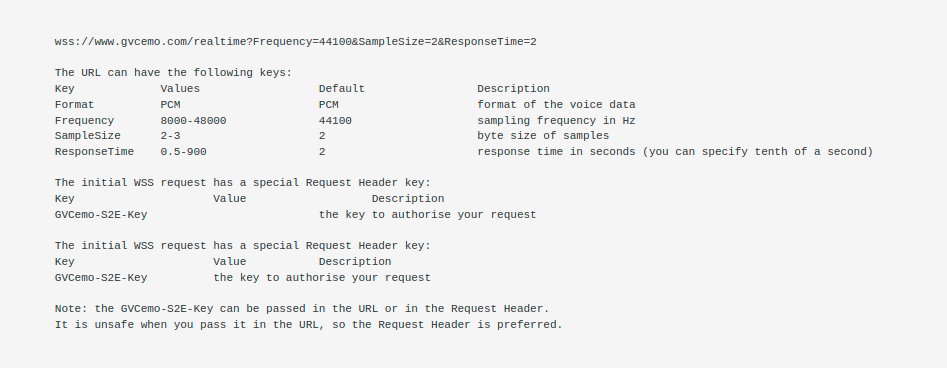
To setup a connection you must open a standard WebSocket connection.
Command
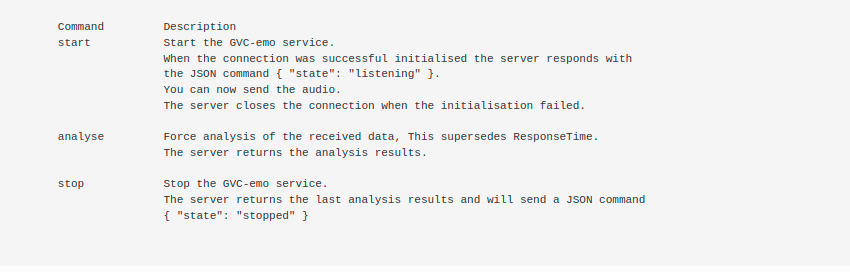
Streaming Commands
When the connection is established you must send commands as text frames to the server. The sound data must be send as data frames. The server sends all the responses as text frames.
Audio
The service supports currently only pure PCM which must be coded between 8000 Hz and 48000 Hz. The sample size can be 2 or 3 bytes (16 or 24 bits). The samples can not be interleaved.
Output response format
The service returns all output in JSON.
The response contains the following standard fields.

Typical response

Example of a conversation
